Declustering Planar Structural Data
If a planar structural data table contains multiple duplicate or near-duplicate measurements, you can create a declustered structural dataset that will make the table easier to work with. Declustering is intended to work with large, machine-collected datasets rather than smaller sets that might be edited manually.
Declustering preserves the original data table and creates the set as a “filter” by applying two parameters: the Spatial search radius and the Angular tolerance.
- The Spatial search radius determines the size of the declustering space. All points inside the Spatial search radius are compared searching for duplicates.
- The Angular tolerance measures whether points have the same or similar orientation. The orientation of all points inside the Spatial search radius is measured and the mean taken. If a point’s orientation is less than the Angular tolerance from the mean, then the point is regarded as a duplicate. The point that is retained is the one that is closest to the mean.
Creating Declustered Structural Data
To create declustered structural data, right-click on the Structural Modelling folder and select New Declustered Structural Data. Select the source data table and a query filter, if required. Set the parameters and the columns you wish to use, then click OK. The declustered set will be added to the Structural Modelling folder.
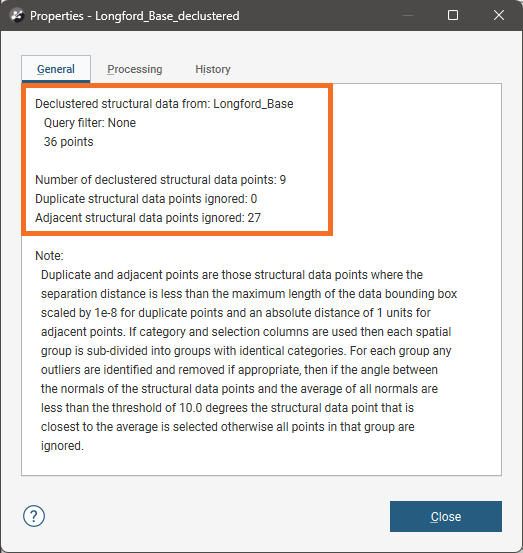
You can find more information on the results of the declustering by right-clicking on the declustered set in the project tree and selecting Properties:
Edit the set by right-clicking on it in the project tree and selecting Edit Declustered Structural Data.
Prioritising Values
When a structural dataset has a numeric column that gives some indication of the measurement’s uncertainty, this column can be used to prioritise values. Select the Priority column and set how the values should be handled.
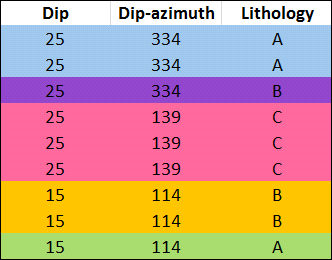
Another factor in declustering the points is the category columns selected. When you choose multiple category columns, all criteria must match for points to be regarded as duplicates. What this means is that points will be kept if they have different category values in just one column, even if they meet the criteria for duplicates established by the Spatial search radius and the Angular tolerance and match in other columns. For example, in this table, assume that applying the Spatial search radius and the Angular tolerance parameters without using the Lithology category results in three points. However, including the Lithology column results in five points, indicated by the colours:
The more columns you select, the lower the likelihood that points will be regarded as duplicate.
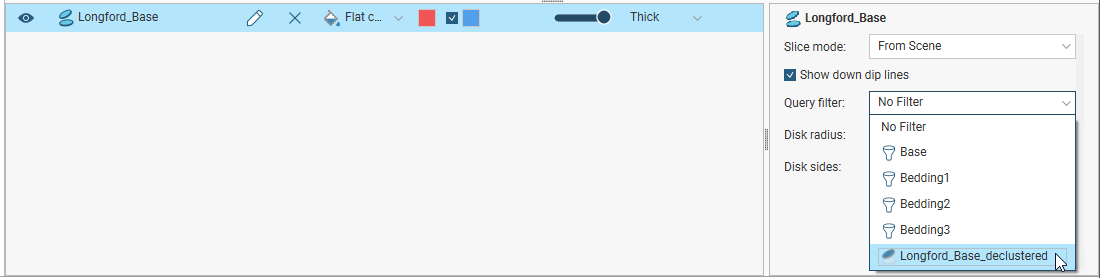
Using the Declustered Data
The declustered data can be used like an ordinary structural data table. However, it is a filter on a planar structural data table and can be used as such when the parent table is displayed in the scene. For example, here the filters available for the planar structural data table include the query filters (![]() ) defined for the table as well as the declustered set (
) defined for the table as well as the declustered set (![]() ):
):